

Today, I'm thrilled to announce the release of gnet v2.0.0, in which we've made plenty of significant improvements and optimizations: added and removed some APIs, redesigned and reimplemented the buffer, optimized the memory pool, etc.
In this blog post, we'll go through the most notable changes to gnet 2.0.
P.S. Follow me on Twitter @panjf2000 to get the latest updates about gnet!
Features
- The built-in codecs have been deprecated and removed, to reduce the complexity and keep gnet simple. From a lot of feedback we've received, this feature does not bring convenience and benefits to users, thus, I decided to take it off from gnet. Cutting those codecs off makes the code on top of gnet more holistic and straightforward, see a simple example for details.
gnet.Connnow implementsio.Reader,io.Writer,io.ReaderFrom,io.WriterToandnet.Conn, apart from that, it also implements thegnet.Socketinterface, providing more API's for users to manipulate the connections.- gnet now supports vectored I/O, allowing users to read from a vector of buffers and write to a single data stream, a vectored I/O implementation can provide improved performance over a linear I/O implementation via internal optimizations. API's for vectored I/O in gnet are
Conn.Writev([][]byte)andConn.AsyncWritev([][]byte, AsyncCallback).
Visit gnet API doc for more details.
Note that some event handlers' name has been changed in gnet v2, learn about the details in the table below:
| Old event handler | New event handler | Note |
|---|---|---|
| OnInitComplete | OnBoot | |
| OnShutdown | OnShutdown | |
| OnOpened | OnOpen | |
| OnClosed | OnClose | |
| React | OnTraffic | |
| Tick | OnTick | |
| PreWrite | - | Deprecated |
| AfterWrite | - | Deprecated |
Optimizations
We redesigned and reimplemented the internal buffers for connections, the diagram shows below:
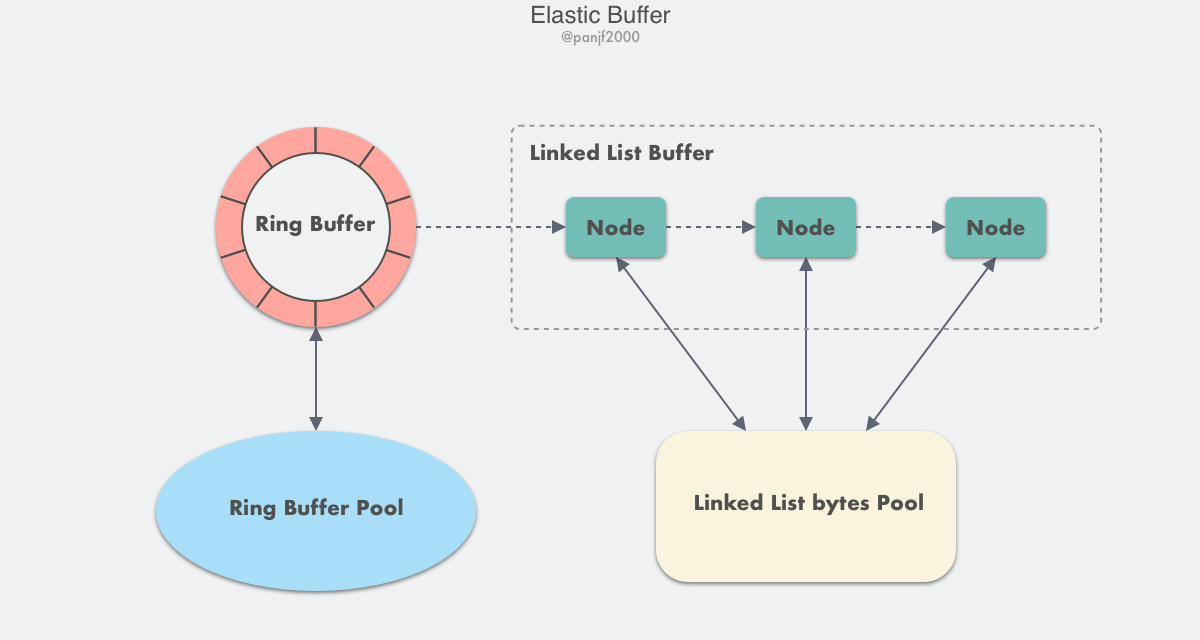
We go from the ring-buffer to the mixed-buffer that combines ring-buffer and a kind of new buffer type: linked-list buffer, which makes it more flexible and efficient, this new elastic buffer can save more memory.
Performance
We've run a simple echo benchmark on Linux between v1.5.3 and v2.0.0, the results are shown below:
Environment
# Machine informationOS : Ubuntu 20.04/x86_64CPU : 8 CPU cores, AMD EPYC 7K62 48-Core ProcessorMemory : 16.0 GiB# Go version and settingsGo Version : go1.17.2 linux/amd64GOMAXPROCS : 8# Benchmark parametersTCP connections : 1000Packet size : 1024 bytesTest duration : 15s
v1.5.3
--- GNET ---Warming up for 1 seconds...2022/02/27 17:23:21 Echo server is listening on 127.0.0.1:7002 (multi-cores: true, event-loops: 8)--- BENCHMARK START ---*** 1000 connections, 15 seconds, packet size: 1024 bytesFortio dev running at 0 queries per second, 8->8 procs, for 15s: tcp://127.0.0.1:7002Aggregated Function Time : count 5795008 avg 0.0025874045 +/- 0.003243 min 1.1692e-05 max 0.093107062 sum 14994.0299# target 50% 0.00169983# target 75% 0.00399017# target 90% 0.00655109# target 99% 0.0141534# target 99.9% 0.0266069Sockets used: 1000 (for perfect no error run, would be 1000)Total Bytes sent: 5935112192, received: 5935112192tcp OK : 5795008 (100.0 %)All done 5795008 calls (plus 1000 warmup) 2.587 ms avg, 386287.8 qps
v2.0.0
--- GNET ---Warming up for 1 seconds...2022/02/27 17:17:32 echo server with multi-core=true is listening on tcp://:7002--- BENCHMARK START ---*** 1000 connections, 15 seconds, packet size: 1024 bytesFortio dev running at 0 queries per second, 8->8 procs, for 15s: tcp://127.0.0.1:7002Aggregated Function Time : count 6729707 avg 0.0022276692 +/- 0.00317 min 1.1902e-05 max 0.07715059 sum 14991.5608# target 50% 0.00132464# target 75% 0.00241054# target 90% 0.00502497# target 99% 0.016105# target 99.9% 0.0291019Sockets used: 1000 (for perfect no error run, would be 1000)Total Bytes sent: 6892243968, received: 6892243968tcp OK : 6729707 (100.0 %)All done 6729707 calls (plus 1000 warmup) 2.228 ms avg, 448593.2 qps
The result shows that the performance of v2 is improved by about 16% compared to v1.x.
Note that this is only a rough benchmark test result and it is done with the simple protocol -- echo, besides, with the benefits from vectored I/O, the performance ought to achieve even higher when it comes to some more complex scenarios, later we will do a more comprehensive benchmark test to get some more accurate results.